
|
Title: Puzzle Solver for Sudoku
Authors: Carmine Oliva, Helgi Siemsen Sigurðarson
Abstract:
We were making a sudoku solver that took in a txt file that held the information about the board and solved the puzzle
using rules and guessing (if it needs to).
We have a previous version of the GUI but we reimplemented it to make the graphic interface
easy to use and with a better design. We also use sites that explain the most important rules
to solve the sudoku.
These are some web sites, they are useful to collect informations about the problem and techniques:
- http://www.sadmansoftware.com/sudoku/solvingtechniques.htm
- http://www.palmsudoku.com/pages/techniques-overview.php
- http://www.sudoku-help.com/Solving-Rules.htm
- http://www.codeproject.com/KB/game/SudokuSolverStrategies.aspx
Our work is based on rules and guesser.
The AI uses logic rules that we got from http://www.sadmansoftware.com/sudoku/solvingtechniques.htm
and if the AI ran into trouble it would guess 1 number and try to use the rules to finish the puzzle if a solution
was not found the AI would "rollback" to before the first choice and pick another candidate. The guessing mechanic
creates a backup of the board to do a "rollback" also it creates a list of candidates and assigns them "blame" when
ever there is another cell in the same row, column or submatrix that has the same candidate.
Some heuristics select the cell to process/analyze/solve; than
we try to apply the main 6 rules (easy-medium level of solver) to find the right value. When no rule can be used
after N interactions, we apply the guesser.
We also made a very efficient data structure to manage cells and values. We made a statistical analysis to find
the most efficient way to solve any puzzle, completely.
It worked well, the AI solved all the puzzles we gave it. It should be able to solve all puzzles that belongs
to the easy/medium level of difficulty. The AI does not guess beyond the depth of 1, manly because
sudoku puzzle aren't supposed to require guessing and if a guess is needed it does not go beyond 1 although this is
not a perfect world so a puzzle could be created that needs 2 guesses and then this AI could not handle it.
Our program should be able to solve any kind of sudoku (for "diabolic" sudoku we can use the guesser). Anyway
we made a system as extensible as possible: it is extremely easy to create a new rule. Our design
should be strong and flexible enough to collect new techniques or updates. Another interesting feature of our solution is
the efficiency: we found a good balance between time-consuming and memory consuming in order to have good performances (using
powerful data structures and a statistical analysis).
[More]
|

|
Title: Rubik's Cube Solver
Authors: Guðni Þór Guðnason, Magnús Ágúst Skúlason
Abstract:
We want to solve a rubik's cube within a reasonable amount of time.
We are using a beginner algorithm that is used to solve the cube by hand.There have been numerous solutions to this problem including a algorithm dubed god's algorithm that solves the cube in 18 moves median.
We starting by reading papers on the god's algorithm but found it to be overly complex for this assignment. We then started to experiment with search for solving the cube but found out it is impractical for a lack of a proper heuristics function. Our final solution was to implement a beginners algorithm which solves the cube by applying predefined rotations when encountering certain patterns.
It works very well, the rotations needed to solve the cube are on average 120 but the time it takes to find it is around 0.03 seconds.
[More]
|

|
Title: CSI Crime Scene Investigator
Authors: Niccolò G. Rossetti, Lorenzo Scagnetti
Abstract:
Our aim was to create a Crime Scene Investigator, a tool able to help detectives in the research of the convict. The detective can input by GUI the scene findings, e.g. specifying whether a gun was found or not. Then the tool can reason on the input data thanks to its Bayesian network and returns the probabilities of the convicted's profile. The profile is returned as a set of offender's characteristics, expressed with a probability (e.g. his sex with a 65% accuracy).
We based our work on two papers (“Bayesian Network Modeling of Offender Behavior for Criminal Profiling Kelli Crews Baumgartner and Silvia Ferrari and C. Gabrielle Salfati, 2008” and “Offender interaction with victims in homicide: A multidimensional analysis of frequencies in crime scene behaviors,
C. Gabrielle Salfati,
490-512,
2003”). These papers analyze single victim/single offender murdering. The authors made the Bayesian network upon police data by applying different algorithms to them. The papers show a 57 nodes network (36 input, 21 output) and the probabilities of the inputs. They talk about a final implementation of the network and tested it against 47 solved cases, obtaining hight confidence levels (see papers).
We have searched for a tool to implement the network and we found NeticaJ. This tool provides a Java API (among others) and a free version. We implemented the Bayesian network and made a friendly GUI. Unfortunately the free version has some limitations, as a maximum of 30 nodes. Moreover we were unable to use its graphical API to show the net. Thus, we reimplemented the net, cutting the number of nodes and adding the information missed from the papers (the authors told us that they were unauthorized to deliver more information, e.g. CPTs). To show the network, we used JavaBayes.
According to the above-mentioned limitations, we achieved our goal. We constructed a nice tool where the user can input the scene findings and have a criminal profile as result. Our work can be extended and made more accurate by changing to another API, having access to the full police's data (to update the data we fixed) and having a crime specialist as collaborator.
[More]
|

|
Title: Artificially Artistic, Putting the Art Back into Artificial Intelligence (Download PDF Version)
Authors: Ásgeir Jónasson, Hrafn Jökull Geirsson, Jökull Jóhannsson
Abstract:
We want to explore the possibilities in making computers artistic, the methods and techniques needed (with emphasis on Genetic algorithms),
what has been done in the past and of course, study state of the art technology in the field. It would also be interesting to discuss what
art fields computers could explore and which ones have any practical value.
Papers that we found online, there is quite a lot of them and they are listed in the end of our paper. A large part of the paper
are speculations, so past experience and our thoughts are our only references in those parts.
Creativity is an integral part of humanity and one that defines us as a species.
Since research in Artificial Intelligence has always been in part aimed at understanding the human mind and trying to replicate some of its functions,
it makes sense to try and understand this quality that defines us and separates us from other species.
Making computers creative is not only a matter of understanding creativity in humans but also how to represent creativity in a computer system,
how to make computers learn from past experience in art creation and most importantly, trying to avoid hard coding what constitutes quality art to give the computer the necessary freedom to be creative, all the while allowing it to learn from human artists and perhaps, cooperate with them.
With all authors having dabbled in music creations and other fields of the arts, some more than others,
it made sense for us to research this field of Artificial Intelligence. In this paper we take a look at how creativity works in humans and how it might be done in computers, see what has been done in the field of artificial art in the past, brainstorm how we might apply some of the techniques we have learned so far (and others) to creative systems and explore what fields of the arts a computer might master and which ones might even be lucrative.
Unintentionally, the main focus in our paper was on the part emotions play in the creative process. This seems to be the biggest problem
with making machines artistic, how they can represent emotions and learn how different elements of artworks can have an emotional effect.
Is was also interesting to see that quite a lot has been done in the field, and we thought that people in general perhaps wouldn't be interested
in making machines artistic, but it seems to be quite the contrary.
Our next step would be to try and implement one of the systems we discussed and we think the musical composer using genetic algorithms would
probably be the most interesting one to try out and perhaps has the biggest potential.
[More]
|
|
Title: Sudoku Solver In C#
Authors: Kristján Tryggvason, Kristófer Kristófersson
Abstract:
The programmed sudoku solver needs to be able to solve sudoku puzzles that it obtains.
Im using C# for the making of the sudoku solver. Other sudoku solvers already exists and are available on the internet. Such as
AI Sudoku Solver
The program takes the sudoku from screen and creates an instance of a class SudokuArray that receives the sudoku and creates a three dimensional integer array that represents the state of the sudoku. The cells of the sudoku are represented with two of the dimensions as row and column and the third dimension represents all the info for a each cell. We can think of it as [row, column, depth] and for the depth 0 we have the numbers that have bin entered into the sudoku already and can range from 0-9 and if the number is 0 then it represents an empty cell. As for the depth of 1-9 represents the possible numbers that can be entered into a cell and if it is set to 1 than that means that the number might be in the cell or 0 if it can not be in the cell. Of course if we already have a number in the range of 1-9 in depth 0 then for all in depth 1 to 9 is set to 0. We also have depth 10 that is just a counter for all the possible numbers in depth 1-9 that is set to 1 so that if depth 10 is 1 then only one number can possible be in the cell and that number is put into depth 0. So the program works by eliminating possibilities in the cells so that we can find what number is to be entered into the cell.
The program worked well though it can not solve all the sudoku puzzles. We only have implemented that numbers are to be entered into a cell if only one possibility is for a cell or if we know that the number is only possible for one cell in the specific row, column or block. And all elimination of possible numbers is from numbers in the same row, column and block. It does not take into account strategies such as naked pairs, y-wing or even knowing that a number will be in a certain row or column of a block even if you donŽt know the exact cell. So further improvements of the code can improve the sudoku solver to solve more puzzles. There is one issue that the textboxes in the interface can take in letters not just numbers that can cause trouble. That is something that should be fixed with further improvement of the code.
[More]
|

|
Title: Solving Einstein's puzzle
Authors: Gunnar Sv. Sigurbjörnsson, Jón Friðrik Sigurðarson, Þorsteinn Þorvaldsson
Abstract:
The problem we aimed to solve was using PowerLoom to solve Einstein's puzzle. However, using PowerLoom to solve this puzzle became to problematic
for us so we decided to implement a solution in C++.
There are five persons, each of different nationality(norwegian, dane, brit, german, swede). Each of them live in a different house,
each house has a distinct color(yellow, blue, red, green, white). They smoke different brands of cigarettes(dunhill, blend, pallmall, prince, bluemaster) and drink different drinks(water, tea, milk, coffee, beer), and they all have a different pet(cats, horses, birds, fish, dogs).
The set of hints we were given:
- The Englishman lives in the red house.
- The Swede keeps dogs.
- The Dane drinks tea.
- The green house is just to the left of the white one.
- The owner of the green house drinks coffee.
- The Pall Mall smoker keeps birds.
- The owner of the yellow house smokes Dunhills.
- The man in the center house drinks milk.
- The Norwegian lives in the first house.
- The Blend smoker has a neighbor who keeps cats.
- The man who smokes Blue Masters drinks bier.
- The man who keeps horses lives next to the Dunhill smoker.
- The German smokes Prince.
- The Norwegian lives next to the blue house.
- The Blend smoker has a neighbor who drinks water.
Abstracting problems like these so we can apply to any kind of logic puzzles.
For PowerLoom the documentation was very poor and noone seems to have solved this puzzle using PowerLoom, so we built on nothing.
For C++ there are many sources regarding this puzzle, and how to use bitwise operations.
What the C++ solution does is creates what we can think of as a table that has 5 houses. Each house can then have 1 color, 1 person, 1 type of cigarettes, 1 type of bewerage and 1 type of pet.
We first insert all the given facts.
We know that the norwegian lives in the first house. The house next to him is blue, so we know that is house nr 2. And then we know the man in the center house drinks milk.
What we then do is start by looking at the first house and try and insert the first fact there. If there is no room for that given fact then we move on to house nr 2 and try to insert it there. We keep doing that until we are out of houses. If we are unable to insert a fact we will undo the last done fact and try find another place for that. When we then find a new place for it we can again try the first fact that failed.
[More]
|

|
Title: Timetable Scheduling
Authors: Grímur Tómasson, Eiríkur Fannar Torfason
Abstract:
Automated timetable generation with a mixed-initiative approach.
For the most part we relied on Chapter 6 in the textbook. In addition we read papers on timetable scheduling.
We chose to approach this as a constraint satisfaction problem and used the min-conflicts local search algorithm to find a valid solution. Focusing on an applicable solution we used realistic data, all courses and classrooms available to the computer science department. After discussing the project with the people who make actual timetables, we went with a mixed-initiative approach, allowing users to make manual adjustments to the generated timetable.
The software solution works surprisingly well.
It is robust and flexible and it can, reliably, generate a valid solution in an acceptable amount of time.
This solution is, however, not a comprehensive solution to timetable scheduling. It solves the generation of a valid timetable, but it does not perform qualitative optimization. In addition to that we simplified to problem somewhat by assuming a uniform duration of classes.
Adding qualitative optimization, using soft constraints, along with additional constraint types would be an interesting avenue for further work.
[More]
|
|
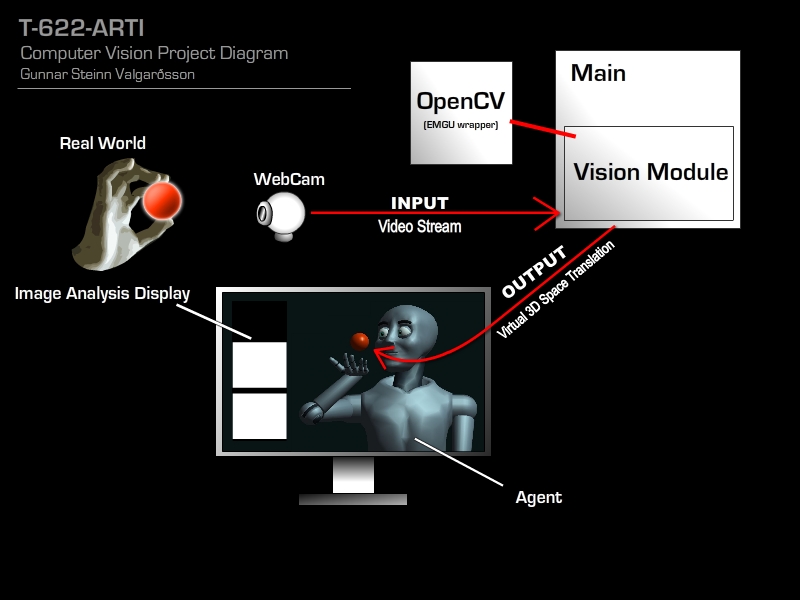
Title: Computer Vision - Object Recognition
Author: Gunnar Steinn Valgardsson
Abstract:
How to translate the position of a real world object into a virtual environment using computer vision.
Existing Resources used: OpenCV, EMGU CV C# Wrapper, EMGU Examples, Unity3D Engine.
Main Sources:
- http://www.emgu.com/
- http://www.lirtex.com/robotics/fast-object-tracking-robot-computer-vision/
- http://www.cs.cornell.edu/Courses/cs4758/2011sp/final%20project/tim_sams.pdf
- http://www.aishack.in/2010/01/color-spaces/
The project focused on the construction of methods to track an orange colored ball and translate its position into a 3D environment. It also focused on implementing various other computer vision methods for use with a 3D developing environment (Motion detection, face recognition, image recognition and shape detection)
Computer vision is getting increasingly important for the development of new types of human-computer interaction. This project focused on the development of a fast tracking method that can track an object that is used to interact with a virtual agent inside a 3D environment.
The work concluded with a vision module that can confidently solve the problem of tracking an orange ball and translate it into a 3D environment.
An interesting next step would be to track more colors and further on add the ability for the agent to answer which color an object is that the user is holding.
[More]
|

|
Title: Football Outcome Predictor
Authors: Finnur Emil Björgvinsson, Þorgeir Karlsson
Abstract:
Precdict football game outcomes using Machine learning and statistical analysis.
We used some popular football statistics from: www.soccerway.com.
We created statistical data based on prior games(just the last 6 ones in most cases) and past meetings. We then created a loss point, draw point and a win point, then we picked the result whose point was closest.
Our goal was to predict the outcomes of football games from the English premier league. The user can submit any two teams and the program would output its prediction. We accomplished this using various statistics and formulas both original ideas we came up with and common methods already used in the footballing world. Because of the degree of uncertainty when looking at sporting events, the predictor can never be 100% accurate. However one team will always have a higher probability of winning and selecting the team that is most likely to win is the ultimate goal of this system.
It worked in about 50% of the cases, this will always need improvement because it can never reach 100%, if it did the game itself would be obsolete. However in a truly random system where it simply guesses the result would be around 33% accurate so our system shows that it is significantly better than when simply guessing results.
This was an interesting project though it could use some more improvements as it stands now. We would like to think of our project as a prototype and a full scale system would have data from the Premier league dating back to its inception in 1992. As of now we only have 677 matches in our data pool and the more matches we have the better our data would be. Also it would be effective to include other leagues such as the Italian and Spanish football leagues. The predictor itself could use improvement and more variables could be examined. A perfect football predictor would be able to look at a near infinite amount of variables since there are so many factors to consider when looking at something like football where at the very least 24 humans affect the outcome of the match.
[More]
|

|
Title: General Purpose Propositional Logic Inference Engine
Author: Helgi Leifsson
Abstract:
Machines that can infer knowledge given a fact or series of facts are becoming increasingly
important. This project solves the problem of inference using propositional logic as opposed to first
order logic, and proof by contradiction using Java as the programming language.
Work based on:
- Knowledge base data structures and algorithms modified from: S. Cheng, A. J. Moon, Wumpus
World: Logic and Partially Observable Environments, 2008, University of Waterloo, Canada.
- Inference and resolution algorithms from: Artificial Intelligence: A Modern Approach, 3rd ed., S.
Russel, P. Norvig, 2010, Pearson, USA
For this exercise the programming language Java was used to implement all the classes and
algorithms necessary. A small test bench for a Wumpus World was built to test the engine to see
whether the engine inferred correctly by whether the agent behaved intelligently or not.
The knowledge base is a linked list structure containing trees of rules that contain facts in the leaves.
For the inference the knowledge base is turned into it‘s conjunctive normal form equivalent, the
complementary of the fact being verified attached conjunctively, and a resolution algorithm run to
resolve all the possible clauses. If the resolution contains an empty clause, then by proof of
contradiction it has been shown that the fact in question can not possibly be false, so it must be true.
As it stands the engine is fully implemented and tests have shown it to infer correctly for simple
things such as whether it has found gold or not. Important issues still open are inferring the locations
of wumpuses and pits as these test most of the logical operators already implemented.
[More]
|
|
|
Title: Emotional Agents in Computer Games (Download PDF Version)
Author: Elín Carstensdóttir
Abstract:
Methods of simulating/emulating emotional behavior, focusing on emotion models.
Related Work and Material: The work of Marsella, S. in the field of emotion models and behavior modeling. Papers by Marsella, S. (et al.), paper on the OCC emotion model by Bartnec, C.
Researched approaches and existing solutions to the problem of simulating/emulating emotional behavior for computer controlled characters in computer games, with a particular focus on emotion models.
Virtual simulations and environments in computer games are becoming increasingly more realistic and sophisticated. A predominant feature in many of modern games is the use of computer controlled characters (NPCs) for the purpose of more dynamic and diverse gameplay. One of the concerns regarding NPCs is that they often lack realistic behavior simulation and natural emotion-based behaviors, especially when interacting with players or other NPCs. The realism that the environment and the appearance of the character create is thereby broken to some extent.
In this paper I will present an overview of suggested solutions to the problem of simulating realistic emotion-based behaviors with emphasis on emotion models.
I found that there are three main approaches when it comes to solving this problem: emotion models, personality models and "brute force" methods such as behavior selection trees.
I concluded that "brute force" methods, such as those dominantly used in game-development today, will not always be sufficient in the future since demands for more realistic NPC behavior are on the rise. To be able to simulate emotion behavior as realistically as possible more sophisticated methods are needed. I believe emotion models to be the most likely successor since they offer more variety and more sophisticated emotional states than "brute force" methods can provide.
In the future it would be interesting to explore and study actual implementations of emotion models in games in more detail, both from academia and industry.
[More]
|

|
Title: Get the yellow brick out!
Author: Guðrún Hauksdóttir
Abstract:
The problem is set on a 6x6 board with vertical and horizontal bricks of different colors. Each square on the board is 50x50 with the coordinates (x,y) ranging from TopLeft=(0,0) down to BottomRight=(400,400). The bricks can move horizontally (after the x-axis) or vertically (after the y-axis). The goal is to get the yellow brick out through the exit in as few moves as possible.
This is the site I used as a role model to build the interface and construct the 10 puzzles used in this project:
http://www.arcadepark.net/34791-Car-Puzzle.html
The problem is known and most often the solution used is A*search or IDA* search with admissible heuristics. This solution is based on A* representation where prior projects in class (prog.2) where used as a base. This project is programmed in .Net using C#.
I implemented A* search but due to lack of time the project is not finished. A list of 10 puzzles in stored in a txt file that is read and parsed into a list of puzzles, each puzzle containing a list of bricks.
The algorithm starts with a State which holds a list of all the bricks in the current puzzle (List). Each State can return a list of all possible successors (childs) so each state works like a node in a list with a set of children.
A heuristic evaluation is used to determine the value of each state – that is how good of a move is the chosen one? The heuristic is determined as so:
- H(state) = (MovesToGoal + MovesMade) * ManhattanDistance + NumerOfBlockingCars.
- G = MovesToGoal= total moves to goal
- F =MovesMade = moves made so far
- NumberOfBlockingCars= is the number of cars blocking the yellow´s brick path out plus one
- Manhattan distance = Cost * (abs(n.x – goal.x) + abs(n.y – goal.y)).
Due to lack of time I decided to simplify the heuristic by having each possible move only one squre up,down,right or left with the cost of 1 for each and every one of them.
I implemented over 1000 lines of code and as stated before did not get the solution to work!
With little more time (which is long overdue) I am confident I could have made the search work better.
The problem is with stack overflow starting from the first treeDepth level = 1, so I´m guessing the problem lies in the size of each state which is probably too big since each state holds a list of all possible moves as a new representation of the current state. The problem is fairly easy to fix but I have no more time left.
Also, I would have to look deeper into the heuristics and the search to make sure I don´t explore dead-end nodes.
[More]
|

|
Title: Thoughts about use of AI in video games (Download PDF Version)
Author: Una Benediktsdóttir
Abstract:
The initial idea was to create an artificially intelligent bot in Unreal Tournament capable of
traveling and navigating by himself using A*. It developed into more the idea of use of AI in shooting
games and a bit of experimentation with it using pogamut and UT2004 in order to become more familiar with the ideas.
Building on existing code used firstly to try to make our own bot but then more of a
playground for experimenting with basic AI bots within Unreal Tournament in order to discover what
it is behind the complicated aspects that drives it. It helped to see some of the main problems,
especially since the codes were not too complicated and the bots were not extremely "intelligent" so
it helped to see the basic issues that one would encounter when beginning to make bots. For
research most information came from existing research on the topic.
Main sources were the internet (of course) and a book called AI Game
Development, Synthetic Creatures with Learning and Reactive Behaviour by Alex j Champandard.
As stated earlier the approach began by working with tutorials in order to learn how to code
our own bot using A* search navigation. This proved to be difficult but nevertheless it did teach me
the basic problems that programmers face when attempting to make good AI for shooting games.
Then the project moved on to more research on the subject and most of the results obtained
through the research supported the problems that I had been facing when trying to code something
respectable for unreal tournament.
The ideas researched were mostly about the overall problems with discovering terrain,
teamwork, reaction and balancing out hunter and prey "instincts".
There are plenty of problems that arise when trying to make an AI for games, and shooting
games are no exception. As a novice it can prove extremely difficult to make anything satisfactory
enough to really be referred to as artificially intelligent. The attempts made in this project were no
exception of this and eventually more research on the subject had to be done in order to really
understand what is needed. Since coding without understanding of the objective can render projects
almost impossible, or at least not as effective as they would be with this understanding, the paper
focuses a bit more on the general issues that seemed to come up within the readings and issues that
were noticed throughout experimentation.
In terms of the initial project, it worked both well and not so well. It was difficult to get the
code to work in the way wanted initially, and eventually I found out that A* search didn’t even need
to be coded since it was already a built in function with pogamut. So in terms of the initial objective,
a bot with A* was made using tutorials and building on existing code, but it wasn’t extremely
impressive since the actual path finding algorithm (which would have been the main challenge) was
already made for me.
However, the second objective, which was to get more familiar with the making and
problems of AI in games, and in particular shooting games was pretty efficiently executed and I
definitely learnt a lot of new things. It was also definitely an experience in which you read something
and you think, “Oh, wow, of course, I can’t believe I didn’t take that into consideration”. As it turns
out, before coding something that is supposed to show artificial intelligence, you need to get your
own intelligence on the subject in order.
[More]
|

|
Title: Morris Game / Mylla
Author: Sigurður Jökull Eydal Tómasson
Abstract:
I wanted to make a game playing agent for 9-men Morris game. And the game environment as well. For this project i looked into search algorithms and heuristics.
I'm using a modified version of A* algorithm, but i came up with the implementation. I found someone who had already made Nine-Men's Morris here, altough i did not base my solution on it. I googled the rules for the game, and used the book AI : a modern approach for the A* algorithm.
programmed the game rules and the gui and made the game playable for humans. And then created a class which the program calls, which recieves the gamestate and returns an action. The search algorithm works by first generating the actions available for the player in the specific circumstances and then uses an evaluation function to simulate the other players move. In order to create a simulation of the gameplaying, and then it looks for paths that lead to mills.
The game is essentially split into three parts.
The player has to choose coordinates to place their piece on, if he gets a mill he has to choose which of the other players pieces he removes. And he also has to move his own pieces.
There are 4 things i took into consideration:
- The Forming of mills;
- Half-formed mills;
- Forming of enemy mills;
- Relative mobility.
So the player tries to maximize the forming of mills and mobility and minimize forming of enemy mills.
It feels like you're playing against someone so i feel i have achieved to create a player that reacts correctly in basic circumstances, but the algorithm can still make stupid mistakes, i think some more fine-tuning would improve it.
I'm happy with the resulting program but i would have liked to look at even more ways ways of doing this, for instance using machine learning to train a system to play the game. Or looking at more search algorithms.
[More]
|

|
Title: Ascr: Windows Process Analysis
Author: Sindri Bjarnason
Abstract:
The Ascr project itself is a console application in C++, below is a screenshot of the default
execution process with some additional paint strokes for "illustrative" purposes.
The default execution consists of the following operations:
- Find and map to memory the training executable (SimpleCPP.exe);
- Scan the training executable and decompose the PE structure;
- Do a dumb scan of the file in memory and determine the boundary in which there is a high
probability of executable code being present;
- Generate “patterns”, which are simple subsets of the executable code sequence;
- If successful, execute the training program and attach to its process using the Debug API.
Attempt to match those patterns in the process memory.
We distinguish between two different approaches to binary analysis, based on whether we
are dealing with programs as a sequence of instructions stored in a physical file or as a process
containing those instructions along with any runtime information required. For physical files, the
approach is denoted as static analysis, and dynamic analysis for process analysis. In both cases, we
are interested in determining the functionality of the binary through some form of analysis. In this
project we tried to determine the functionality of Windows processes that originated from PE files
(Portable Executables).
Originally my approach was to focus solely on information available during runtime of the
process, however, as it turns out that method is sub optimal since the volume of data retrieved
expands too rapidly.
There is plenty of research material available on the topic of binary analysis, the following
are the relevant ones to this project:
- Creating a basic debugger: http://msdn.microsoft.com/en-us/library/ms679288(v=VS.85).aspx. The Debug API interface from Microsoft;
- An in-depth look into the Win32 Portable Executable Format: http://msdn.microsoft.com/en-us/magazine/cc301805.aspx. The most detailed description of the Windows PE format;
- Carbon based lifeforms – Set theory: http://www.youtube.com/watch?v=23iuPKuPd30&feature=related. A solid tune;
- X86 instruction set (intel): http://ref.x86asm.net/coder64">http://ref.x86asm.net/coder64">http://ref.x86asm.net/coder64. A quite comprehensive html resource about the intel instruction set and the decoding process;
- Beaengine: A library for decoding Intel instructions.
The Ascr initially was built around the Debug API from Microsoft and has a functional
debugger interface within the project file. A debugger is not a functional analyzer on its own, so it
became apparent that references from the original PE file were needed. At that point, I focused
my efforts on writing a parser for PE executables, using the MSDN article above.
The main result is a conjecture which appears to hold for the simple training executable. It
can be explained a bit formally as follows:
Let sj be a sequence of instructions, such that si ϵ Ppe and si = { oj, oj+1, … , oj+n }. Let ν denote
the variance of sj for all j's, ν = [0 … 1]. The variance is a measurement to the stability of the
sequence sj in terms of the path through sj during runtime execution.
A sequence sn has ν = 0, iff for all oi ϵ sn, we can predict the exact path through sn and the
state of Prt at all times. A trivial example would be a nop sled or no-operations:
snop = { 0x90, 0x90, … , 0x90 } <=> Prt = { i+1, i+2, …, i+n }, ν(snop) = 0.
For all “first generation” sequences with ν = 0, we can map them directly to a set Ppe' = { D1,
D2, … , Dn }, where Di is a higher-level representation of that sequence. For other sequences with ν
> 0, we apply the following algorithm:
Let sk be a sequence where ν(sk) > 0 and |sk| > α, α is the largest single instruction. Then we
have an index Δ, such that sk = { o1, o2, … , oΔ , … , on } => s'k = { o1, o2, … , oΔ } and ν(s'k) = 0,
s''k = {oΔ , … , on } and ν(s''k) > 0. Since ν(s'k) = 0, mapping sk into Ppe' is based on determining
the functionality of s''k. We know the entry to s''k from s'k from our Δ value and first try to
see if we can reiterate this procedure on s''k, which if successful means that s''k is a new
pattern. Since we are not emulating s''k our algorithm is complete. It will return two
different sets, A and B. A contains the patterns for which ν = 0 and B the patterns for which
ν > 0. The set B is the source of all the variance in Ppe. By isolating that set, we can focus
the Ascr runtime analysis on those patterns, since by our conjecture, we can already
resolve for A.
Essentially, dynamic analysis boils down to analysis on the set B, which Ascr tried to
accomplish through knowledge based engineering of the data gathered when executing the
patterns of B. However, I did not have enough time to see it happen.
[More]
|

|
Title: STRIPS planning for Contract Bridge bidding
Authors: Árni St. Sigurðsson, Baldur Blöndal, Pétur Ólafur Aðalgeirsson
Abstract:
We want to try using STRIPS-like operators to make descriptive bids for a given bridge hand and bid history.
To our knowledge this is a fresh approach to the problem.
We managed to implement lazy-evaluation to structure bidding conventions. We made a robot class that was convention-card-abstract and a convention-card class representing the bid system. Each bid would carry with it an implication for the cards in hand. We did not make an inference engine to infer the implication. We used reflective Python programming heavily.
We realized that we should modify the robot to pass the hand *and the bid history* to the convention card functions for evaluation but lacked time to implement such deep surgery.
[More]
|
